No, Utility Classes Aren't the Same As Inline Styles
Half a decade after the first commit of the pioneering ACSS, utility-first CSS is more popular than ever. With success comes many adepts but also a fair share of criticism. It’s a good thing: polarized opinions mean topics matter enough for people to care. Healthy debate contributes to identifying weaknesses and fueling growth, while indifference would let it stagnate and die.
As an early-defender of utility-first CSS (video version), I love reading constructive critiques that challenge my views and get my problem-solving juices flowing. But despite numerous attempts at debunking common fallacies, utility-first enthusiasts keep on having to reply to a staggering amount of misconceptions. And by far, the most tired, overused cliché is that utility classes are just inline styles.
In my 2018 article, I touched on this specific belief among many others. At the time, it seemed like the easiest one to rectify, the one that would soon disappear because of how easy it was to expose. But persisting falsehoods remind us that nothing is ever obvious, and we should come up with better explanations on why utility classes and inline styles don’t compare, despite bearing a vague resemblance.
Inline styles only apply to the elements they’re declared on
Perhaps the biggest limitation with inline styles is that they can only affect the element they’re on. This is a crucial difference with utility classes.
As with any CSS declaration, inline styles are subject to inheritance. They can impact children if they declare an inheritable property.
<article style="color: darkblue">
<header>
<h2>Blade Runner 2049</h2>
</header>
<section>
<p>
Officer K (Ryan Gosling), a new blade runner for the Los Angeles Police
Department, unearths a long-buried secret that has the potential to plunge
what's left of society into chaos. His discovery leads him on a quest to
find Rick Deckard (Harrison Ford), a former blade runner who's been
missing for 30 years.
</p>
</section>
</article>The inheritable color property affects any child element which doesn’t explicitly declare the property itself.
Aside from that, inline styles only have a local impact. This is because you can only declare styles, not rules. You’re not in a style sheet or within an embedded <style> block, meaning you can’t write selectors. It cuts you from writing styles for pseudo-classes and elements, more complex selectors using combinators, media queries, or animations.
Conversely, utility classes live in style sheets. They have access to the same powerful features as any other CSS class. For example, they can declare styles for pseudo-classes and elements.
<style>
.on-hover\:text-darkblue:hover {
color: darkblue;
}
</style>
<article>
<header>
<h2>Blade Runner 2049</h2>
</header>
<section>
<p>
Officer K (<a class="on-hover:text-darkblue" href="#">Ryan Gosling</a>), a new
blade runner for the Los Angeles Police Department, unearths a long-buried
secret that has the potential to plunge what's left of society into chaos.
His discovery leads him on a quest to find Rick Deckard (Harrison Ford), a
former blade runner who's been missing for 30 years.
</p>
</section>
</article>A utility class can declare styles for pseudo-classes and elements.
When people think about utility classes, they usually picture simple non-nested selectors with single-declaration rulesets. But while this can apply to part of a utility first CSS codebase, this ignores how creative and powerful you can get with functional classes.
For example, utility-first CSS framework Tailwind CSS provides .group-hover classes to let users style children elements when their parents, marked with a .group class, are being hovered. To do so, they leverage nested selectors. Such behavior would be impossible with inline styles.
.group:hover .group-hover\:bg-current {
background-color: currentColor;
}Nested selectors are helpful to compose more complex styles with utility classes.
Nothing prevents you from going more complex than that, and use deeper nesting, selector lists, or CSS combinators. Utility classes are about single responsibility and controlled effects, not about restricting access to powerful features.
For example, the following utility class .with-siblings:text-darkblue applies the same color on itself and its siblings using multi-selectors and combinators. With inline styles, you’d have to declare the color on every desired element.
.with-siblings\:text-darkblue,
.with-siblings\:text-darkblue ~ * {
color: darkblue;
}This ruleset leverages multi-selectors and combinators to create a utility class.
Another use case is media queries. A decade ago, Twitter Bootstrap popularized breakpoint-based classes, allowing users to declare conditional states based on the viewport size. Classes like .col-md-4 are declared inside a media query, so they only apply within a specific size range.
<div class="container">
<div class="row">
<div class="col-md-8">.col-md-8</div>
<div class="col-6 col-md-4">.col-6 .col-md-4</div>
</div>
</div>Bootstrap grids use media queries to create layout variations across devices of different sizes.
There are plenty of available use cases with media queries, including print styles, user preference, feature availability, and more. With a utility-first approach, you can leverage these features to create functional classes that only apply under a given set of conditions.
@media (hover: none) and (pointer: coarse) {
.on-touch\:block {
display: block;
}
}
@media (orientation: landscape) {
.when-landscape\:hidden {
display: none;
}
}
@media (prefers-color-scheme: dark) {
.dark\:bg-darkblue {
color: darkblue;
}
}You can make conditional classes by declaring them within media queries.
Inline styles don’t have access to media queries. They’re only available within style sheets or <style> blocks, so it’s impossible to style conditionally with just inline declarations.
Inline styles can’t be processed
When it comes to CSS and productivity, pre- and post-processors are among the best innovations of the last decade. Of the 11,000 respondents to State of CSS 2020, 89% would use Sass again.

Usage ranking for pre- and post-processors in State of CSS 2020.
CSS pre-processors like Sass, Less, and Stylus let users leverage imperative programming features such as variables, loops, functions, and more, to write clearer, DRY-er code by compiling a superset language into valid CSS. Post-processors—like PostCSS—on the other hand, augments CSS after the fact by taking valid CSS and transforming it for different purposes—backward compatibility, scoping, auto prefixing, linting, you name it.
Utility classes are declared separately, so they’re great candidates for processing. For example, Uniform CSS is built entirely with Sass. If you’re willing to write custom utility classes, you can use pre-processors to write less code, group features, and more.
@media (hover: none) and (pointer: coarse) {
.on-touch\: {
&block {
display: block;
}
&flex {
display: flex;
}
&grid {
display: grid;
}
}
}
$font-weights: (
'regular': 400,
'medium': 500,
'bold': 700,
);
@each $name, $weight in $font-weights {
.font-#{$name} {
font-weight: $weight;
}
}The programmatic capabilities of pre-processors help write utility classes more efficiently.
Tailwind CSS, the leading utility-first framework, was designed to work primarily as a PostCSS plugin. It uses several PostCSS plugins itself, such as PurgeCSS to drop unused classes at build-time, or postcss-selector-parser in their JIT compiler.
While you could technically write tools to process inline styles within HTML, none of the existing mature tools provides any official and actively maintained solution for that. The CSS pre-/post-processing ecosystem largely relies on separate style sheets, where it brings the most value. At the time of this writing, there’s virtually no production-safe way to process inline styles.
Inline styles don’t cache well
You could say that inline styles do cache because you can cache HTML, which would be correct. However, this is a highly inefficient strategy, which doesn’t compare to caching CSS.
Content and style have radically different growth rates. Content grows linearly (at least), often much faster. If there’s anything to cache, it usually doesn’t last long.
For example, a news site like the New York Times publishes hundreds of articles every day and updates posts in real-time. The homepage uses the no-cache cacheability directive. It does use a CDN, like many sites that need high speed and high availability for their content, but sets maximum age of 30 seconds for anything in the cache to be considered fresh. It makes it virtually impossible for a regular user to retrieve the same file twice when visiting the same page.
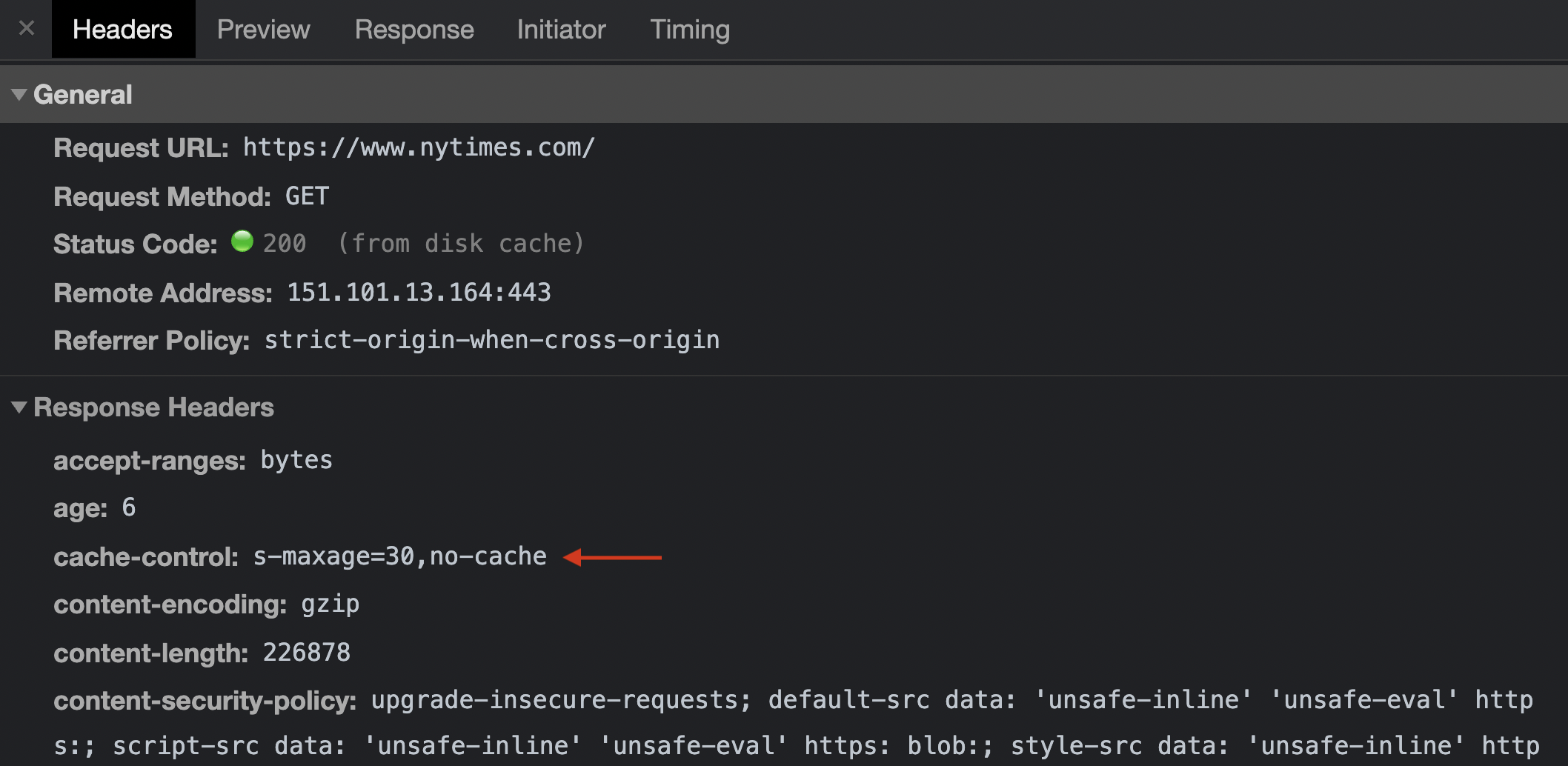
The page served at nytimes.com has a TTL of 30 seconds.
Their global style sheet, however, is a different story. The cacheability directive is set to public (which isn’t necessary when using an expiration directive, yet still denotes intent here), but more interestingly, is set to be considered fresh by the CDN for… a year!
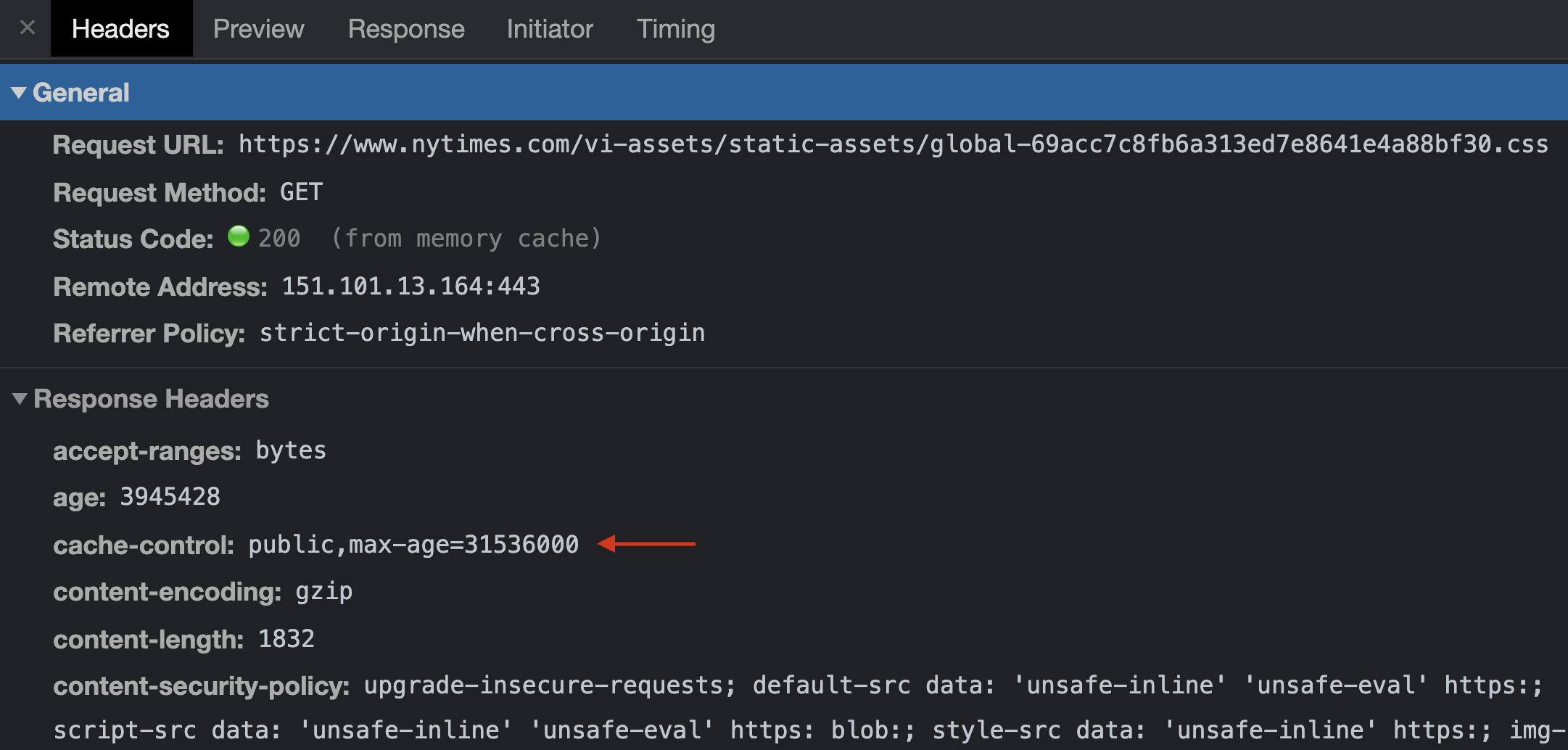
The global styles on nytimes.com can stay in cache for up to 365 days.
On some pages, the New York Times serves other style sheets with a much lower max-age directive (usually 60 seconds). Most of these are dynamically generated by Svelte, a JavaScript UI library that lets you write scoped CSS. These assets contain a content-based hash in their file name that automatically busts the cache when the content changes, so it’s still unclear to me why they don’t have longer TTLs. If anybody has the answer, let me know on Twitter!
This well demonstrates how we expect style to age compared to content. There are differences in caching strategy depending on the CSS methodology you use, but conceptually speaking, on a content site, what it looks like typically lasts much longer than what it says.
Going one step further, let’s take a content site that does use utility-first CSS: the Tailwind CSS documentation.
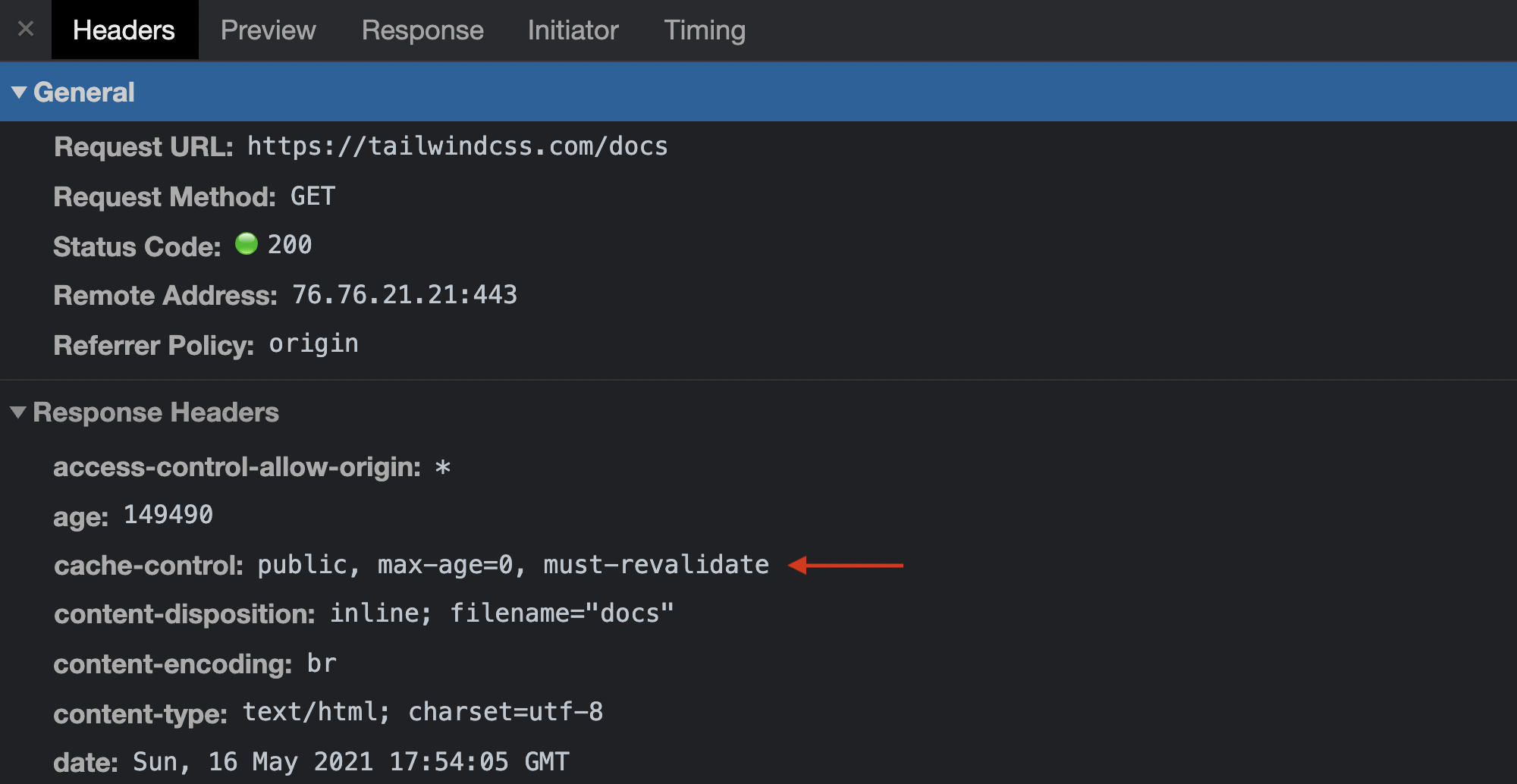
The page served at tailwindcss.com/docs has a TTL of 0 seconds.
The home page has a max-age of 0 with a must-revalidate revalidation directive. This is the default Cache-Control value set by Vercel, the edge network that Tailwind uses, to avoid browser caching and always ensure fresh content. In simpler terms, this content page needs to be as fresh as possible.
When you look at the styles for that same page, the strategy is radically different.
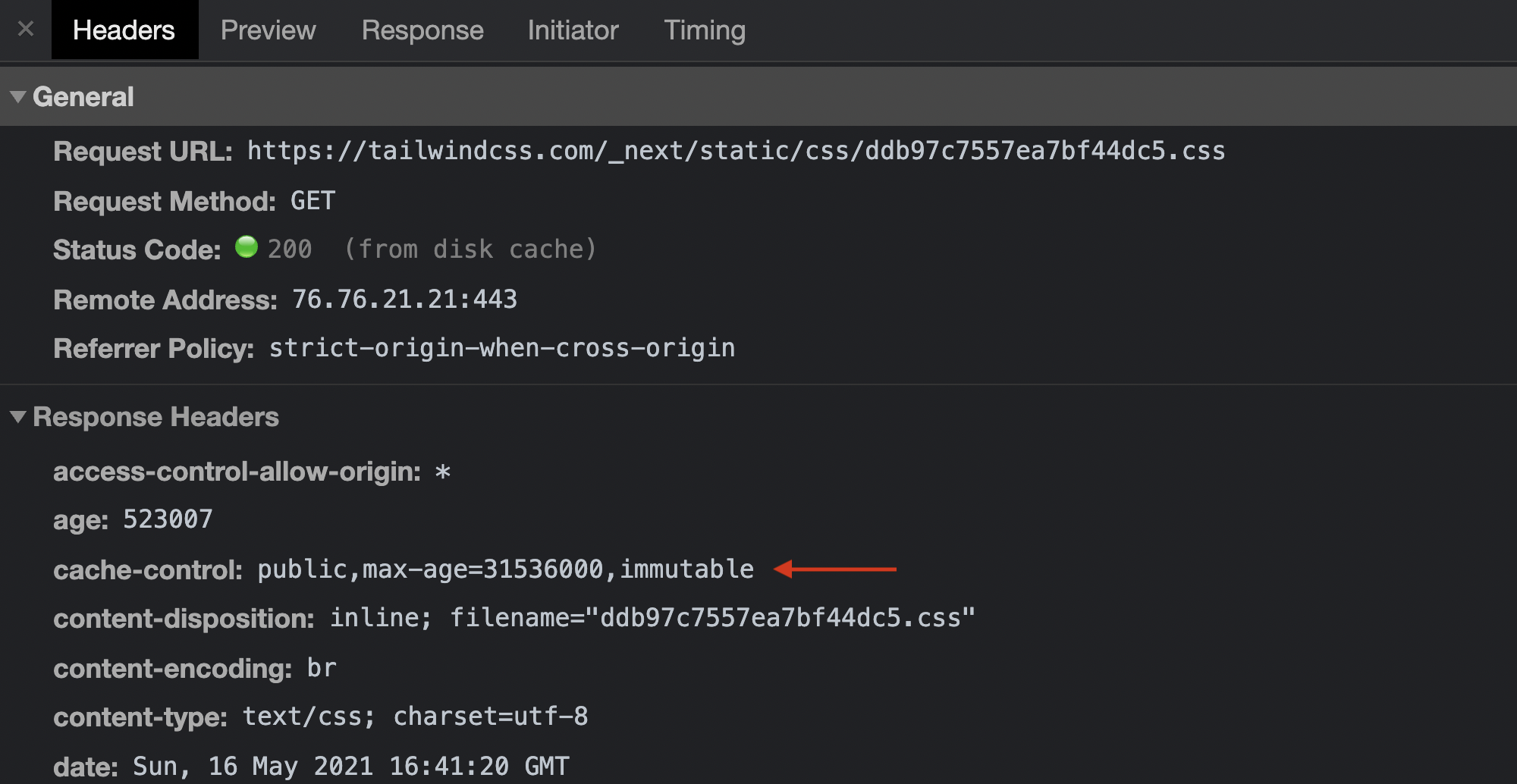
The styles on tailwindcss.com/docs can stay in cache for up to 365 days.
As with the New York Times, styles on the Tailwind docs can stay in cache for up to a year. It also declares an immutable revalidation directive, indicating that the response won’t change over time. Coupling a max-age of one year with an immutable revalidation directive is the equivalent of saying “please cache this forever”, as the HTTP 1.1 spec won’t let you declare values longer than that. In other words, these style sheets can be served from the cache for as long as possible because they’re not expected to change.
“Why go down the rabbit hole of static file caching when we’re talking about inline styles?”, you might wonder. The point here is to demonstrate with real use cases and metrics that HTML and CSS caching aren’t equivalent because they serve different purposes. You can cache an HTML page, so you can technically cache inline styles. Yet, this is a failing strategy considering this HTML page will need to revalidate for content reasons, way before you even touch the styles.
Caching styles in CSS files is much more efficient because, by nature, their content stays in the same state longer. It comes at the “cost” of an additional HTTP request, but with persistent connections and multiplexing, the impact on latency and CPU are often unnoticeable for the end-user.
Utility classes grow logarithmically as you reuse existing “design tokens” even when you build new features or create new pages. Utility classes work wonderfully with aggressive caching strategies. In contrast, the location of inline styles makes it pointless ever to cache them.
Inline styles are unlimited
As explained in In Defense of Utility-First CSS, inline styles allow you to do anything you want. There are no rules, no guidelines, no design system, and no way to enforce anything. You keep on duplicating the same solutions to problems you’ve already solved.
<section>
<article style="padding: 5px 8px; color: darkblue">
<p>A new chapter. A triumph. A cinematic miracle.</p>
<footer>
<p style="font-size: 13px; font-style: italic">
Posted on
<time datetime="2021-05-06 12:00">May 6, 2021</time>
by Olly Richards.
</p>
</footer>
</article>
<article style="padding: 5px 8px; color: darkblue">
<p>
In the end, for all its pleasures, it's difficult to view Blade Runner
2049 as anything but an elaborate echo of the original, neither true
sequel nor reboot, unclear of its own identity.
</p>
<footer>
<p style="font-size: 13px; font-style: italic">
Posted on
<time datetime="2017-10-30 12:00">October 30, 2017</time>
by Melissa Anderson.
</p>
</footer>
</article>
</section>Inline styles repeat the same solutions, with a greater chance of inconsistencies.
Utility classes belong to a CSS architecture, with rules and boundaries. No matter how small, they’re part of a strategy and compose a service for developers to use and reuse. If your product designer decides on a sizing scale for the project, utility classes won’t let you deviate because they’re limited. They’re a direct projection of what’s allowed in the project’s design system, a library of authorized tokens for you to mix and match.
Inline styles don’t have a strategy. They’re escape hatches, useful when you need to assign dynamic styles, build demos, or make something work quickly. They’re inherently limitless because they need to be—they’re your last resort when you need to break the rules. And as such, they stick out like a sore thumb, an eyesore that constantly reminds you to clean up your mess whenever you peek at the code.
Inline styles are one thing at a time
Because they’re usually small, have functional names, and live in the HTML, utility classes feel similar to inline styles to many of those who encounter them for the first time. But contrary to popular belief, utilities aren’t always single-property classes.
Back when the only way to build grids was using floated blocks, the clearfix trick became one of the first widely used utility classes on the Internet. The .clearfix class has no semantics; it’s a purely presentational utility. Yet, despite being atomic, it requires several declarations.
.clearfix:after {
content: '';
display: table;
clear: both;
}One of the modern versions of the clearfix trick.
Utility classes can declare as many styles as necessary to do their job. They’re usually small because they’re single-purposed, but that’s an effect, not a design principle. When slicing a CSS codebase into a hyper modular design system, it’s natural for the resulting design tokens to be one-liners. But because it’s the norm doesn’t mean it’s the rule, and many utilities trump that trend.
Examples from the Tailwind CSS and Bootstrap codebases:
/* In Tailwind */
.truncate {
overflow: hidden;
white-space: nowrap;
text-overflow: ellipsis;
}
.sr-only {
position: absolute;
width: 1px;
height: 1px;
padding: 0;
margin: -1px;
overflow: hidden;
clip: rect(0, 0, 0, 0);
white-space: nowrap;
border-width: 0;
}
.inset-0 {
top: 0px;
right: 0px;
bottom: 0px;
left: 0px;
}
/* In Bootstrap */
.text-hide {
font: 0/0 a;
color: transparent;
text-shadow: none;
background-color: transparent;
border: 0;
}A few multi-declaration utility classes in Tailwind CSS and Bootstrap.
Inline styles declare one property at a time (they can also declare CSS variables, but that’s a marginal use case). These styles don’t mean anything. They don’t describe atomic visual concepts, they declare individual CSS properties, and that’s it. In opposition, while utility classes aren’t semantic, they’re still abstractions, conveying meaning and intent.
Apples and oranges
Constructive, documented criticism is not only healthy; it’s also necessary. We have nothing to gain by ignoring the shortcomings of the tools and methods we use. However, it’s easy to fall for false equivalences and shaping flawed reasoning from them.
In yet another insightful Twitter thread, Mathias Verraes says:
Your brain rewards you for classifying new information into existing buckets. Looking for similarities is lower energy than understanding new differences. […] Proclaiming that the new idea is the same as the old idea, gives you permission not to investigate it deeply, stick to the existing reality where you are an expert in the old idea, and the new ones are merely repackaging of your insight.
Unless making discoveries is your job, there are few incentives for you to spend energy on distinguishing new concepts from known patterns. Equating utility classes and inline styles is more comfortable than digging deeper to understand the differences. This bears even more true if you don’t instantly see any other benefit with utility-first CSS, which could otherwise pique your curiosity.
Mathias follows up:
There’s such a firehose of information, that keeping up with even a single topic is impossible. We should be forgiven for not knowing and understanding and keeping up with everything, even if our job is knowing and understanding and keeping up with everything. […] But let’s try to make a habit of this: when you feel “Oh I get it, it’s just like…”, then follow up with “So what makes the new thing different from the old thing?”
Limiting what information to spend brainpower on is not laziness but self-preservation. Being a developer is exhausting, especially in web. It’s okay to deliberately pass on something, not be interested, or decide that now isn’t the right time.
The key, however, is to be honest about it. Admitting you didn’t (yet) go deeper into a topic to shape an informed viewpoint is a healthier reaction than making snap judgments so you can claim you have an opinion. It also participates in normalizing not knowing, which creates a welcoming atmosphere for beginners, and fights the imposter syndrome we all seem to struggle with.
